In the past years I've worked on quite a number of machine learning and deep learning models. I know my way around Python, Data Science, CUDA and other stuff that comes along with a job in AI.
However if you're a regular developer who doesn't care about building your own models, but feel that AI could solve some important problems for you, what do you do?
It turns out that there are quite a few tools that allow you to solve problems with AI without actually learning anything about machine learning.
In this post I will show you how you can automatically tag images using the Computer Vision API that is part of the Cognitive services offering from Microsoft.
What does the Computer Vision API offer?
A typical use case that people think of when they talk about computer vision is the ability to identify what is in a picture.
The computer vision API allows you to do that. But there's quite a bit more. Microsoft's Computer Vision API is capable of tagging pictures to tell you what's in the picture.
On top of that:
- You can ask for a caption for your image
- Find people's faces in a picture
- Estimate a person's age
- Estimate the gender of people in a picture
- Detect whether an image is offensive
- Find out various properties about an image, such as dominant color, possible accent colors.
- Extract text from images
- Detect objects in the image
For now I want to focus on image tagging, but the other features are just as easy to use.
What's the idea behind computer vision
As you can imagine, detecting objects and tagging images is hard job for a computer. You need a neural network to do this. That's exactly what Microsoft is doing.
They trained a model on a massive dataset for various kinds of jobs that you can perform with the API. This gives you, as a developer, access to a model that is capable of detecting a very wide range of things in pictures.
Normally, it would take you months to train this kind of model. And of course you'd need a massive amount of data that takes years to collect. But if you're Microsoft you have access to this mountain of data, because you are running services like Bing that indexes millions of images every day, that are tagged by humans.
So even if you could train the model yourself, the Computer Vision API is a very affordable and much better performing alternative for image classification jobs.
How to get started with the computer vision API
Let's get started with your first computer vision project. First you need to create a new resource on the Azure Portal to access the Computer Vision API.
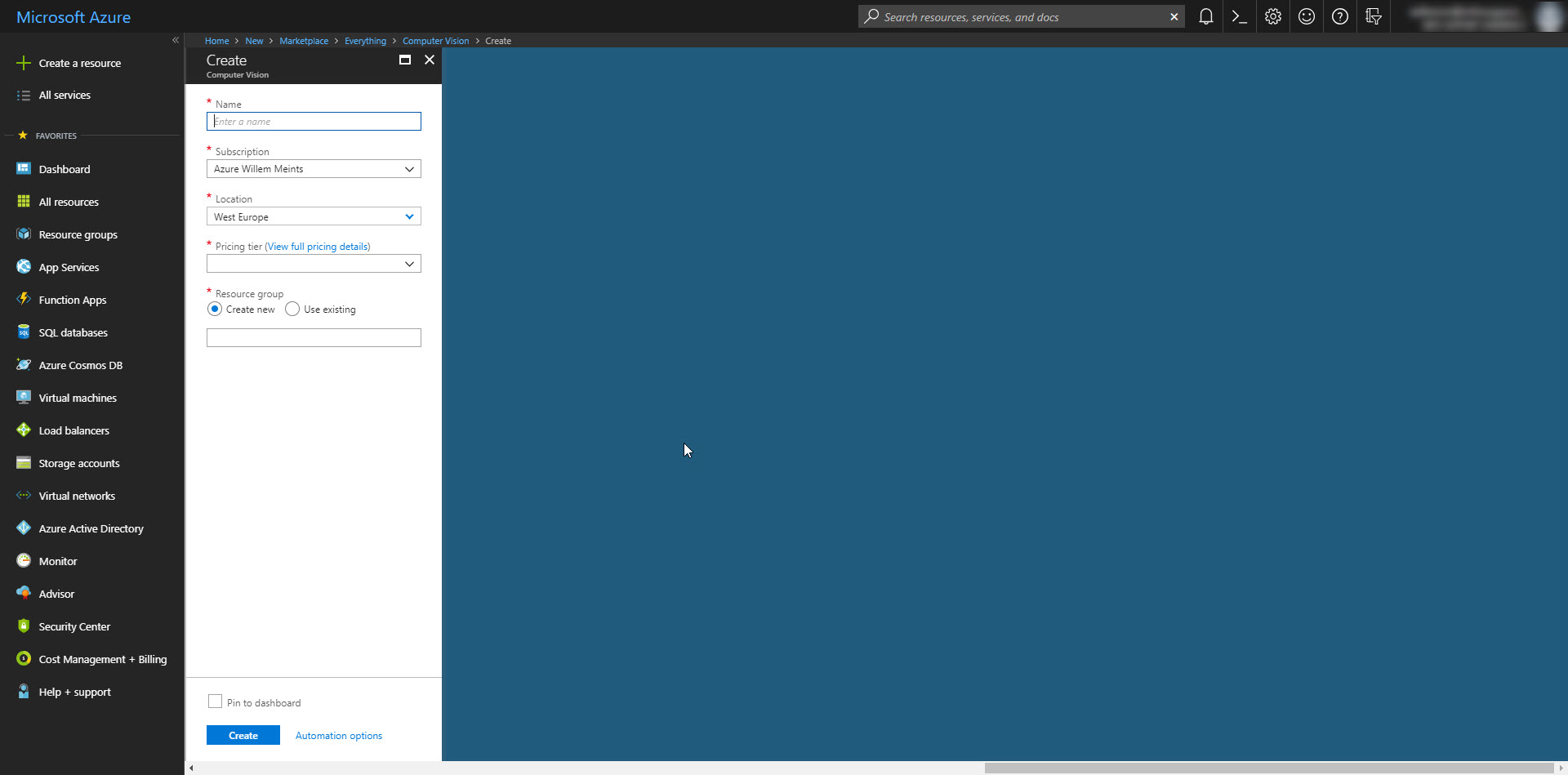
Search for Computer Vision API and click on it to create a new resource of this type. Give it a proper name and click create to deploy it in your subscription.
Notice that there are two possible pricing tiers that differ largely in how many calls per minute you can make to the Vision API. There's the S0 tier that allows 10 calls per second and the F0 tier that allows 20 calls per minute with a 5K maximum per month. Of course the S0 tier is the most expensive. And the one with the highest performance.
My suggestion, stick with F0 tier as long as you can. You can easily monitor application usage and switch at any time if you need to. It saves quite a bit of money.
Create your C# project
Once you have created the new Computer Vision API resource, let's take a look at how to use it in your C# project.
You can use the Computer Vision API from regular .NET Framework on Windows, Universal Windows apps and .NET Core with a Nuget library that microsoft published.
To use the Computer Vision API add the Microsoft.ProjectOxford.Vision package from nuget.
Now you can access the Computer Vision API. Create a new instance of the VisionServiceClient and provide it with your API key.
var visionClient = new VisionServiceClient("<api-key>");
To analyze an image, invoke the AnalyzeImageAsync method. This takes either a stream or a URL to the image and returns whatever features you ask it to analyze.
var imageFeatures = new[] {
VisualFeature.Tags, VisualFeature.Description
};
var results = await visionClient.AnalyzeImageAsync(imageStream, imageFeatures);
In the sample above we asked the vision API for a description and a set of tags. Other options for image analysis are:
- Color - The dominant color and accent colors
- Faces - The faces in the photo
- Adult - Whether an image contains adult content
- Categories - The categories for the image
- ImageType - The image type information such as file format
The output of the AnalyzeImageAsync method is an instance of AnalysisResults and contains data for the image. Depending on the visual features you requested you may get no data in some properties.
To give you a sense of what's in the results, you can extract multiple captions from the Description.Captions property. The Description.Tags property contains the set of tags for the image without a confidence score. If you need the confidence score, access the Tags property on the results object.
Domain specific tagging
Sometimes you don't want a general set of tags for an image. For example, if you're tagging pictures of celebrities you want to relevant tags in that domain.
You can do this by using the AnalyzeImageInDomainAsync(imageStream, model). The first argument is the stream or URL for the image. The second argument is the name of the domain specific model to use.
There are currently to domain specific models:
- Celebrities
- Landmarks
It is important to note that this method is only useful if you are tagging images in one of these domains. The models used are not capable of producing general tags.
Also, you can't specify visual features in this method. So you are limited to tags.
If you're interested in a list of possible domain specific models you can invoke the ListModelsAsync method on the Vision API Client.
Extract text from an image
The Computer Vision API contains more than just logic to analyze images for tags and a caption. You can also extract text from an image. To achieve this, run the RecognizeTextAsync method against your image like so:
var results = await _visionClient.RecognizeTextAsync(imageStream, "en");
The output of this method is an instance of OcrResults and contains the text extracted from the image. You have to iterate over the Regions property on this object to access the individual areas of text in the image.
For example, the following piece of code concatenates all text in an image together as one string:
var allText = String.Join(" ",
results.Regions
.SelectMany(x=> x.Lines)
.SelectMany(x => x.Words)
.Select(x => x.Text)
);
A fun fact, each region, line and word has a bounding box attached to it. Which makes it pretty easy to map out the layout for the text. Maybe do something interesting, like process it differently based on the location on a page.
Conclusion
The Computer Vision API is great when you want to build a solution that requires photo analysis of some sort. The models that Microsoft trained for this purpose are really good at tagging images, recognizing faces and other important things you'd expect from a Computer Vision API.
I think that the whole Cognitive Services suite fills in a big spot for Developers who would like to use some kind of AI in their software, but don't want to learn neural networks or machine learning.
Give it a try and let me know what you think!