Trying to come up with a good model for a machine learning solution can be quite tedious. You'll need to first come up with the right data, then there's the preprocessing and if that's not enough, you need to try multiple models to find one that works best for your problem. There must be a better way right?
In this post I'll show you how you can use a new feature in Azure Machine Learning Service to help find the right model to solve your machine learning problem without writing any code.
We'll cover the following topics in this post:
- How Automated ML works
- Setting up an experiment with Automated ML
- Deploying a model trained with Automated ML
Let's get started by looking at how Automated ML works to help you speed up the process of building a machine learning model.
How Automated ML works
At the core of Automated ML is a process that performs a number of steps for you:
- First, a number of features is selected for training
- Then, a model is trained and evaluated on a key metric
This is what you'd expect from the process of training and evaluating a machine learning model.
What makes Automated ML special is that it uses an intelligent algorithm to try several combinations of features, pre-processing steps, and algorithms to train a bunch of models. After trying out several models it will then select the best model based on the key metric and return that as the result.
All you need to do is:
- Define the kind of problem to solve
- Provide a dataset to use for training
- Select what metric to use for selecting the best model
- Configure how much time to spend on the selection process
In the past, you could already set up an Automated ML experiment from code. But Microsoft made things easier by providing a clean user interface as part of Azure Machine Learning Service so you can run Automated ML experiments without writing any code.
Setting up an experiment with Automated ML
Let's take a look at how to set up an Automated ML experiment in Azure Machine Learning Service. You'll need to have an Azure Machine Learning Workspace set up for this. There's a good tutorial in the documentation to get you going.
When you've created a workspace you'll be able to find in the portal by navigating to the resource group that you've created and then selecting the workspace. When you select the workspace you'll see a layout similar to this:
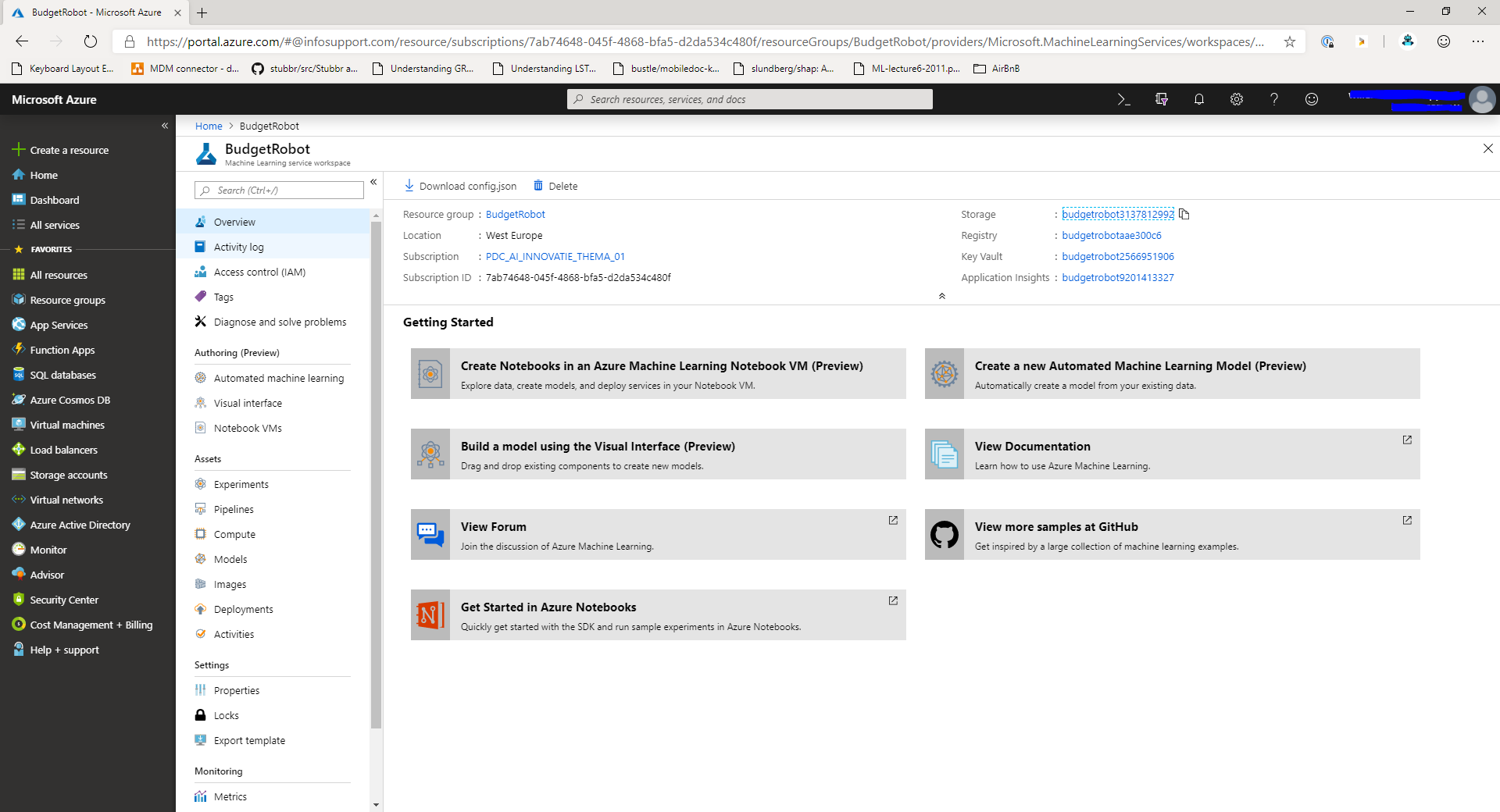
In the machine learning workspace, navigate to the Automated Machine Learning dashboard in the menu on the left. You'll get an overview of all the Automated ML experiments in your workspace.
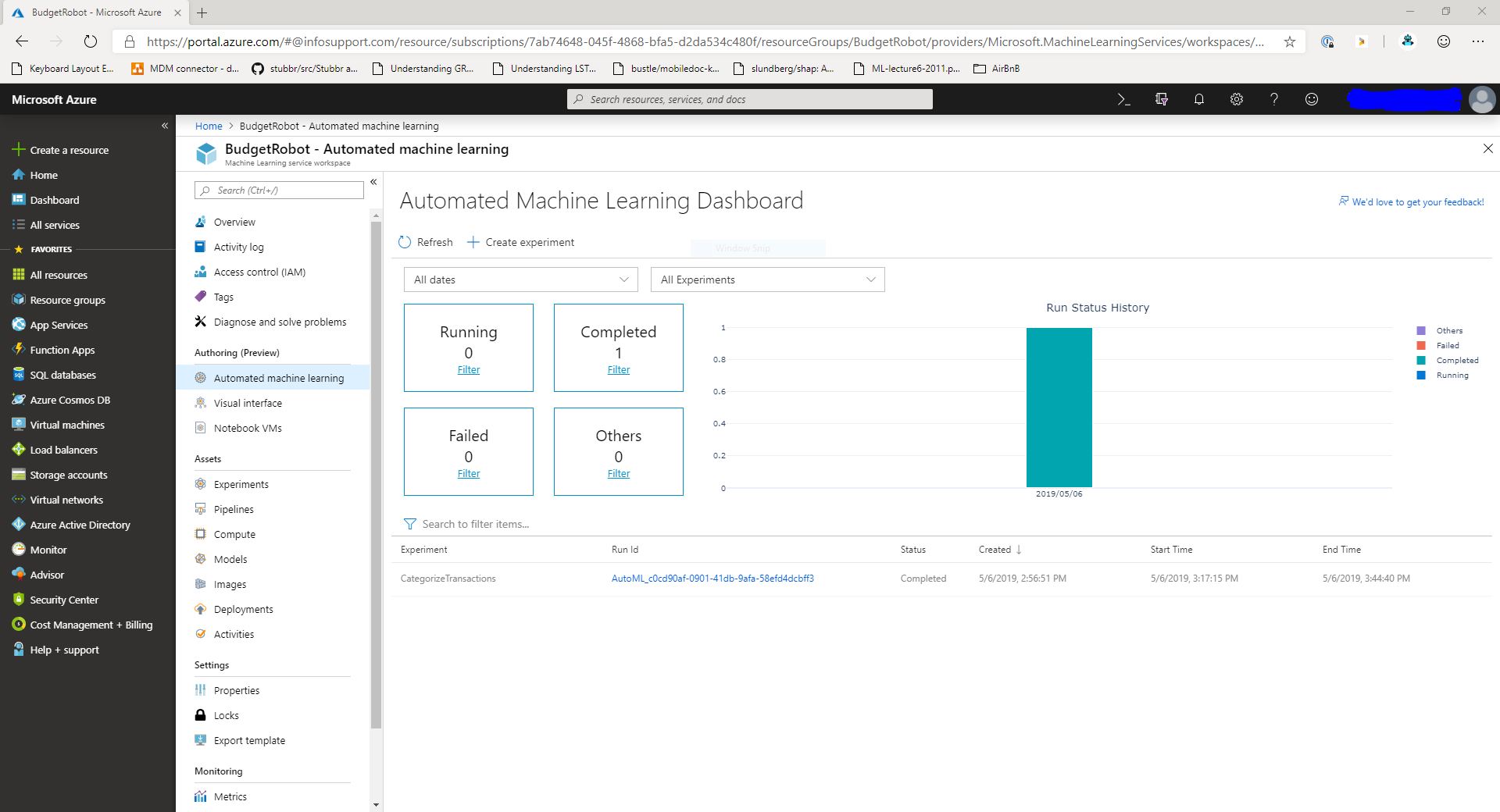
To create a new experiment, click the Create Experiment button at the top of the page. You'll get a new screen that looks like the image below.
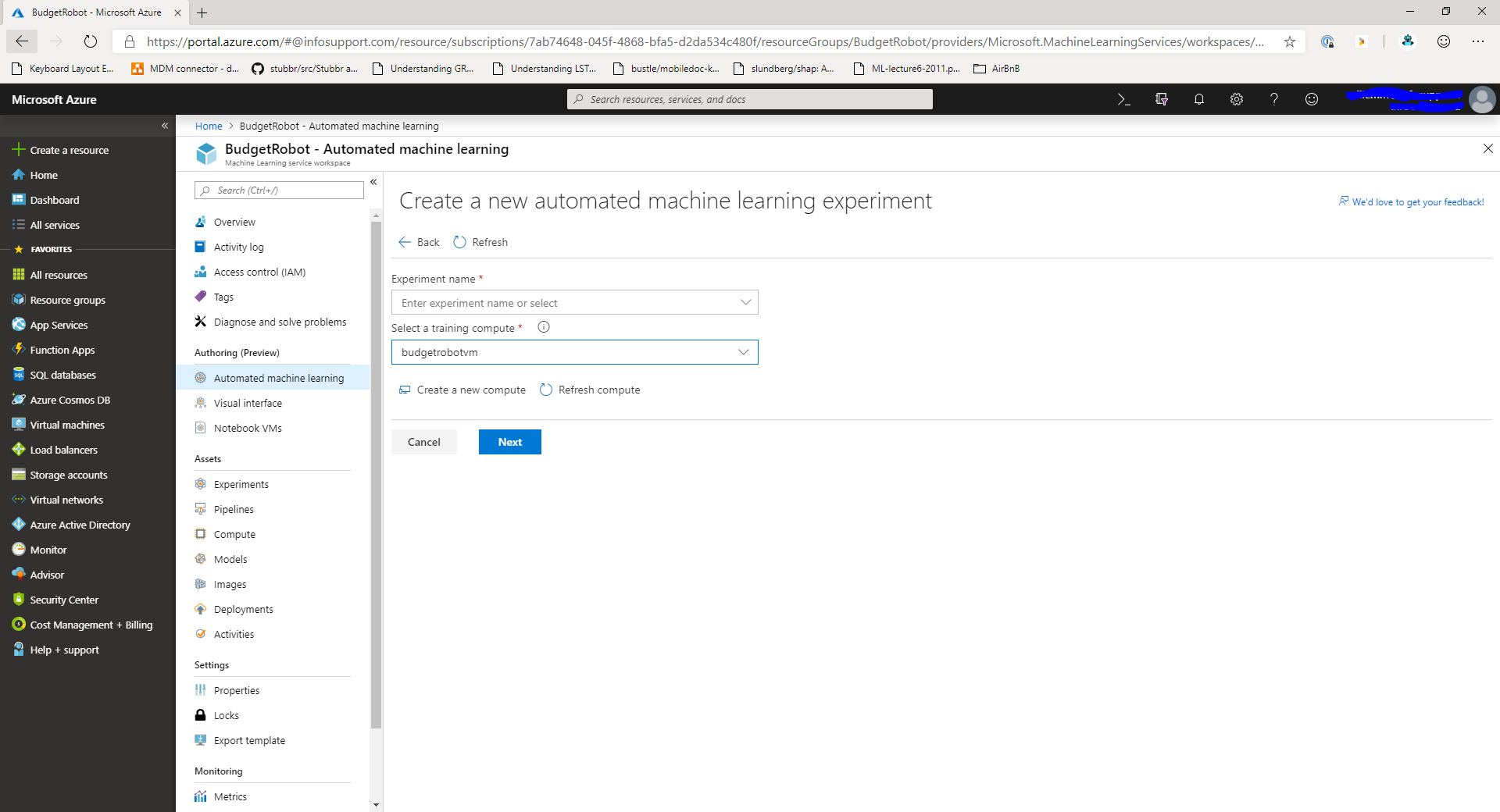
In this window you can enter the name for the experiment and select a compute target to run the experiment on. If you haven't got a VM yet, you can create a new one right from this screen using the Create a new compute button.
The compute target that you create here is a linux VM of a size that you can choose. It will run the docker image that contains the Automated ML code. Depending on the size of your dataset and the number of models to try, it will take a long time on smaller VMs, so I suggest you pick a decent size VM for your experiment.
After you've created or selected the training compute target, click the Next button to move to the next step.
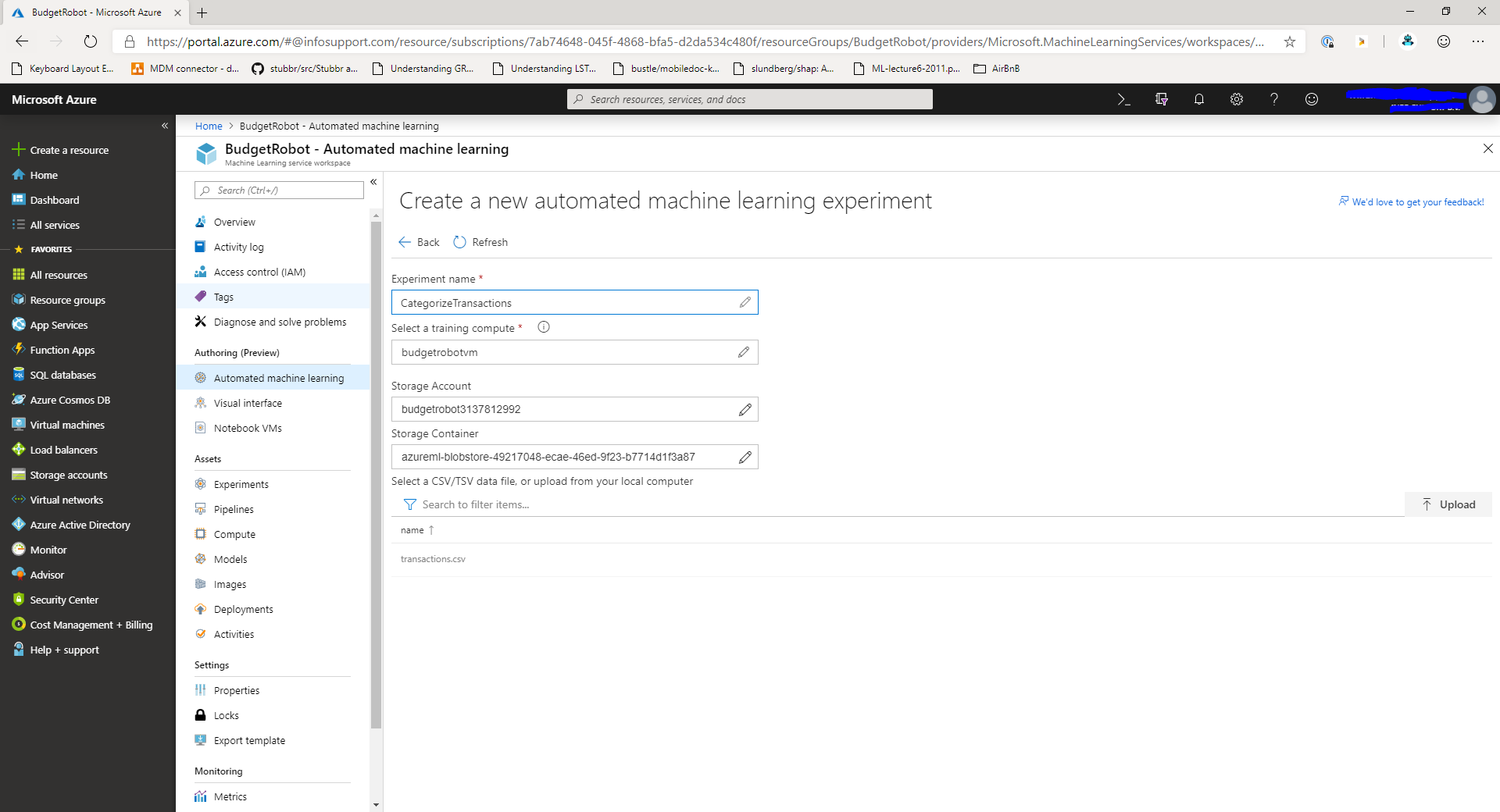
In the next step, we'll select the data source for the Automated ML experiment. Currently, only Azure Blob Storage is supported. If you happen to have data in SQL Server or Cosmos DB you'll have to export it to CSV first.
You can either select an existing file from this step or upload a new file to the storage account.
Select the file you want to run the experiment. You'll now see the details of the input file and be able to select the columns for your experiment.
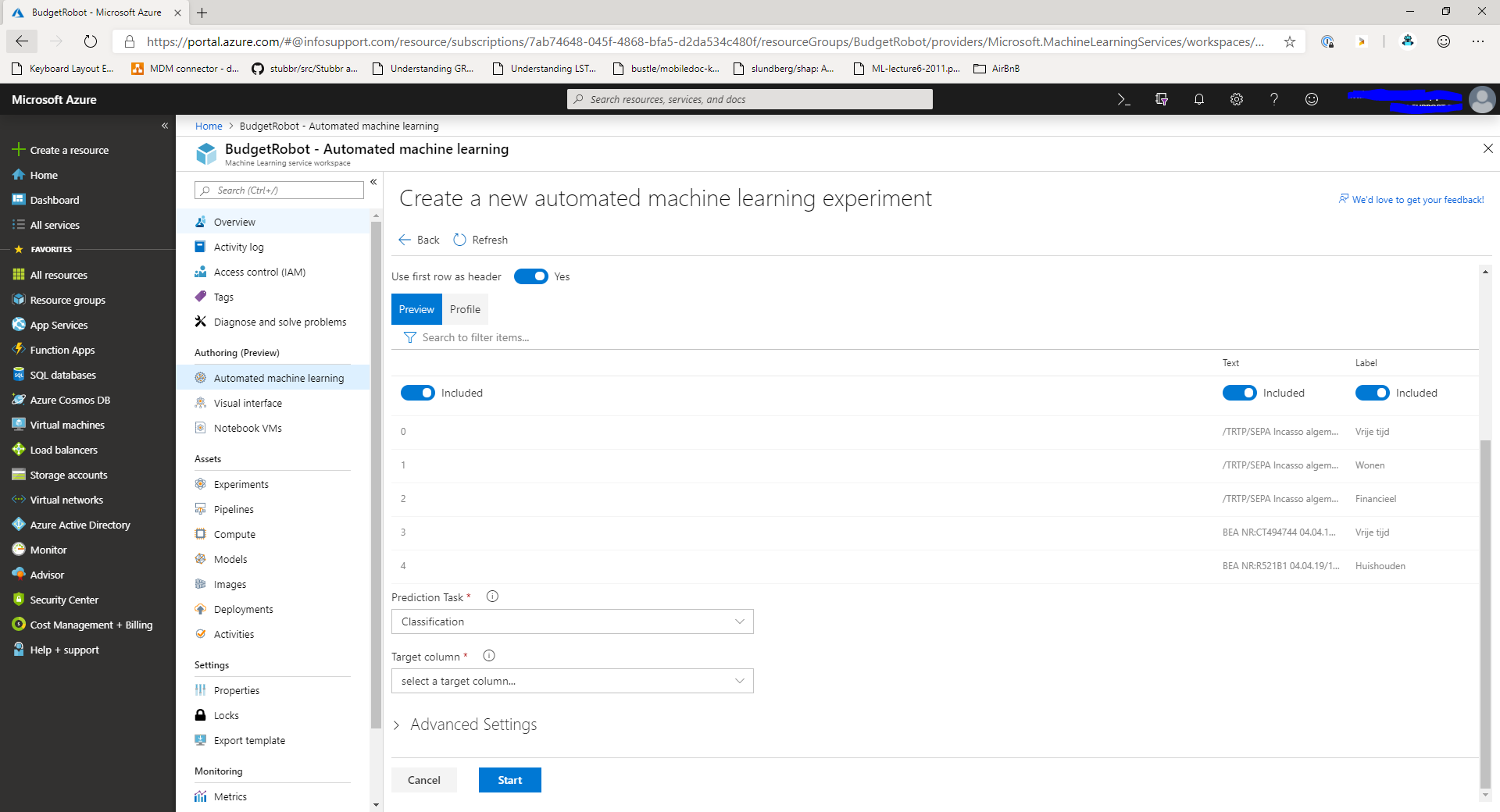
Include or exclude any columns for the experiment by clicking the toggle button above the column. Next, select the kind of problem you're trying to solve. Then, select the target column from the dropdown.
At this point you're good to go with the experiment. If you want, you can configure more advanced settings by expanding the Advanced Settings panel.
Click Start to run the experiment on your compute target. Please note that it will take a while to set everything up. In my case it took about 10 minutes to prepare the experiment and another 40 minutes to train all possible combinations of models.
Once your experiment is running you can see the output in the dashboard. It will look similar to this screenshot:
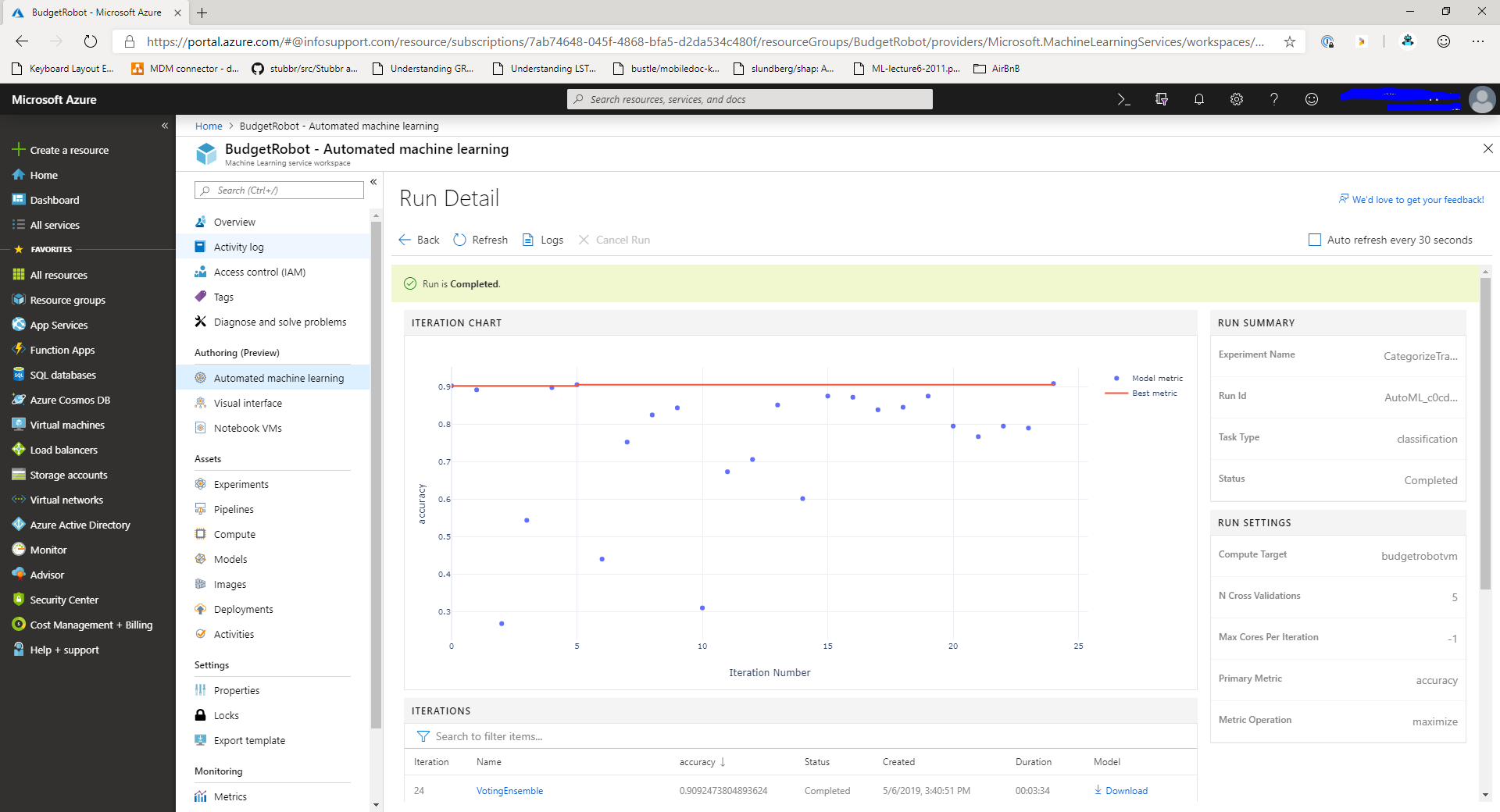
In the middle of the page you'll see a chart displaying how each experiment is doing based on a key metric. Below the chart you can see a list of models and pre-processing combinations that are tested in the experiment. On the right, you can find the settings for the experiment.
When you select a model from the list of models at the bottom of the screen you'll be presented with the details for that particular model:
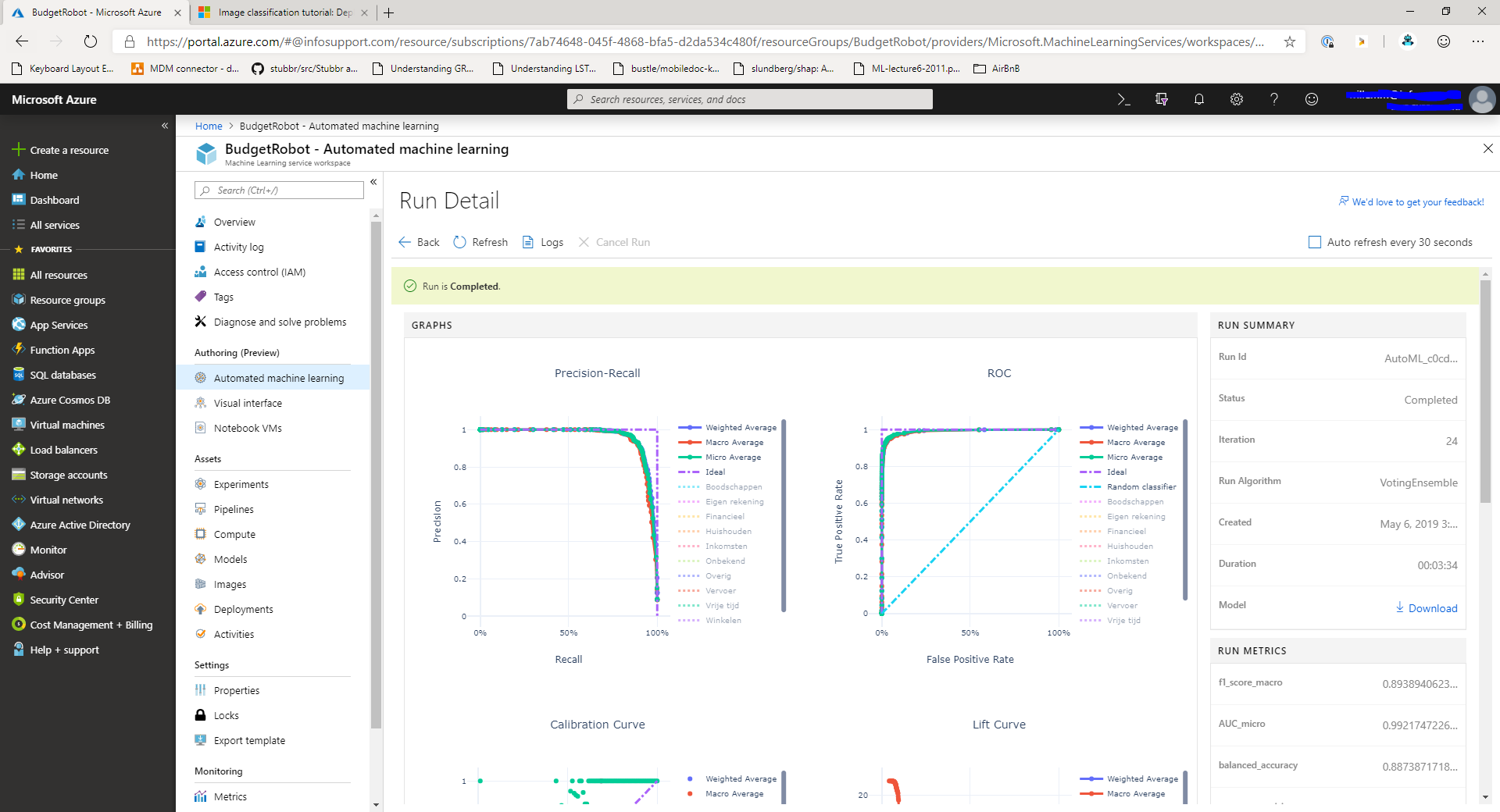
In this screen you can explore different metrics that were collected for the model. For example, you can check out the precision/recall curves and F1-scores for classification models.
Once the experiment is completed and you're happy with the results you can deploy the best model to production, let's take a look at that next.
Deploying a model trained with Automated ML
Currently, there's no automated way of deploying the model obtained through an Automated ML experiment in the portal. This is something that I expect will change as the preview of this feature progresses.
Registering the trained model
To deploy a model trained using Automated ML, you'll have to download it. From the Automated ML experiment details screen, click the download button to the right of the model that you want to deploy.
By clicking the download button you'll get a model.pkl file that contains the scikit-learn pipeline for the trained model.
In order to use the model, we'll need to register it in the model registry. Navigate to the Models section of the Azure Machine Learning Workspace. You'll see a screen similar to this:
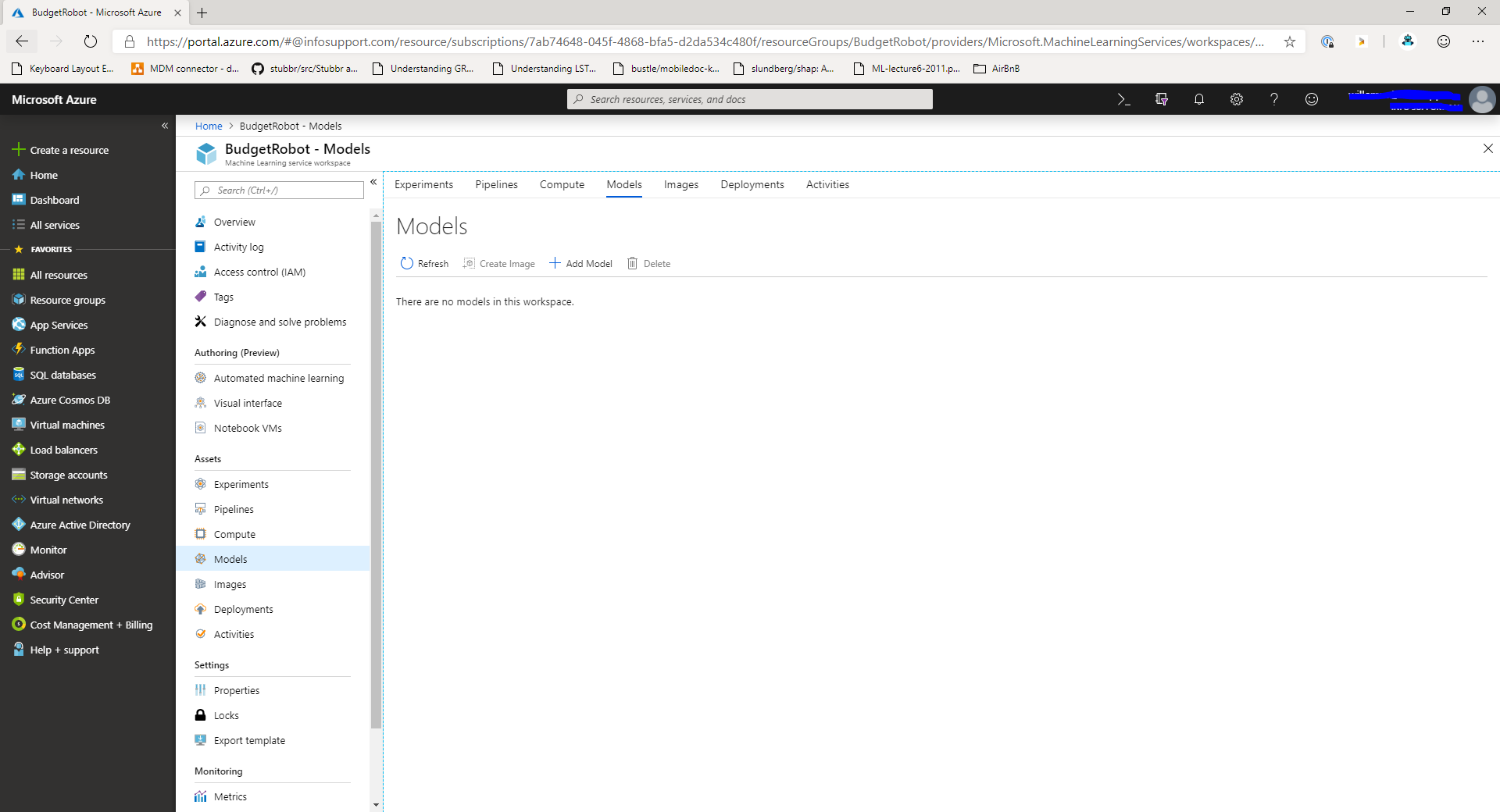
In this screen, click the Add model button. This will take you to the next screen:
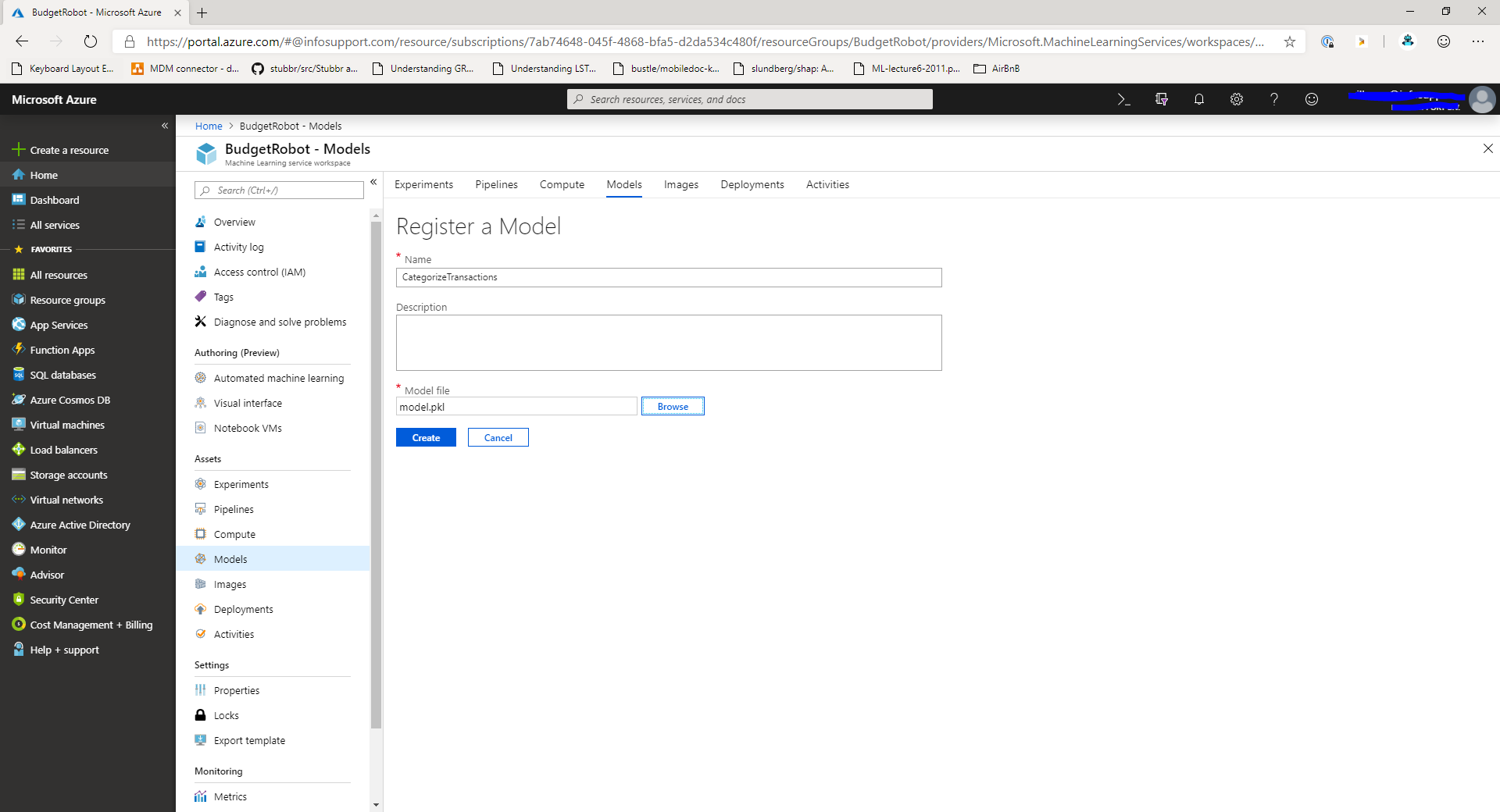
In this screen, provide a name for the model and select the model.pkl file that you downloaded earlier. Click the Create button to store the model in the model registry.
Once the model is uploaded, you'll be taken to the model details screen which displays the details of the model.
Now that you have a model, let's create a script to use the model. We'll need to perform a couple of steps to use the model:
- First, we'll need a scoring script for the model
- Next, we'll need an environment file that describes the used libraries
- Finally, we need to create an image for the model on the portal.
Creating the scoring script
Let's start with the scoring script. Create a new file, score.py with the following contents:
import json
import numpy as np
from sklearn.externals import joblib
from sklearn.linear_model import Ridge
from azureml.core.model import Model
from inference_schema.schema_decorators import input_schema, output_schema
from inference_schema.parameter_types.numpy_parameter_type import NumpyParameterType
def init():
global model
model_path = Model.get_model_path('CategorizeTransactions')
model = joblib.load(model_path)
input_sample = np.array([['sample text']])
output_sample = np.array(['label'])
@input_schema('data', NumpyParameterType(input_sample))
@output_schema(NumpyParameterType(output_sample))
def run(data):
try:
result = model.predict(data)
return result.tolist()
except Exception as e:
error = str(e)
return errorThe scoring script should contain two functions: init, and run. The init function is invoked when the application is started. The run function is used to make predictions with the model.
In the init function we retrieve the model from the model registry by the name that we choose earlier. After that, we load the model using the joblib.load function.
In the run function we get in a sample of data from the client stored as a numpy array. We run the sample through the model's predict method to get a prediction. We then return the generated output to the client.
It's important to note that the output should be JSON serializable. You don't have to serialize the data yourself, the runtime will take care of this process automatically.
Now that we have a scoring script, let's set up the environment dependencies for the model.
Creating the environment requirements file
In order to run the scoring script, Azure ML needs to know about the libraries that you're using in the scoring script. In the case of Automated ML there are a few standard dependencies that you'll need.
The environment requirements are stored in a conda_env.yaml file with the following contents:
name: project_environment
dependencies:
- python=3.6.2
- pip:
- azureml-defaults
- scikit-learn
- inference-schema[numpy-support]The anaconda environment file is used to set up an anaconda environment inside the docker container that will host the model. It contains a specification for all the used python packages.
Once you have the environment file, it's time to deploy the model as an image in the Azure Machine Learning Workspace.
Deploy the model as an image
You can deploy a model as an image by clicking the Create image button at the top of the screen when you're looking at the model details in the Azure Machine Learning Workspace.
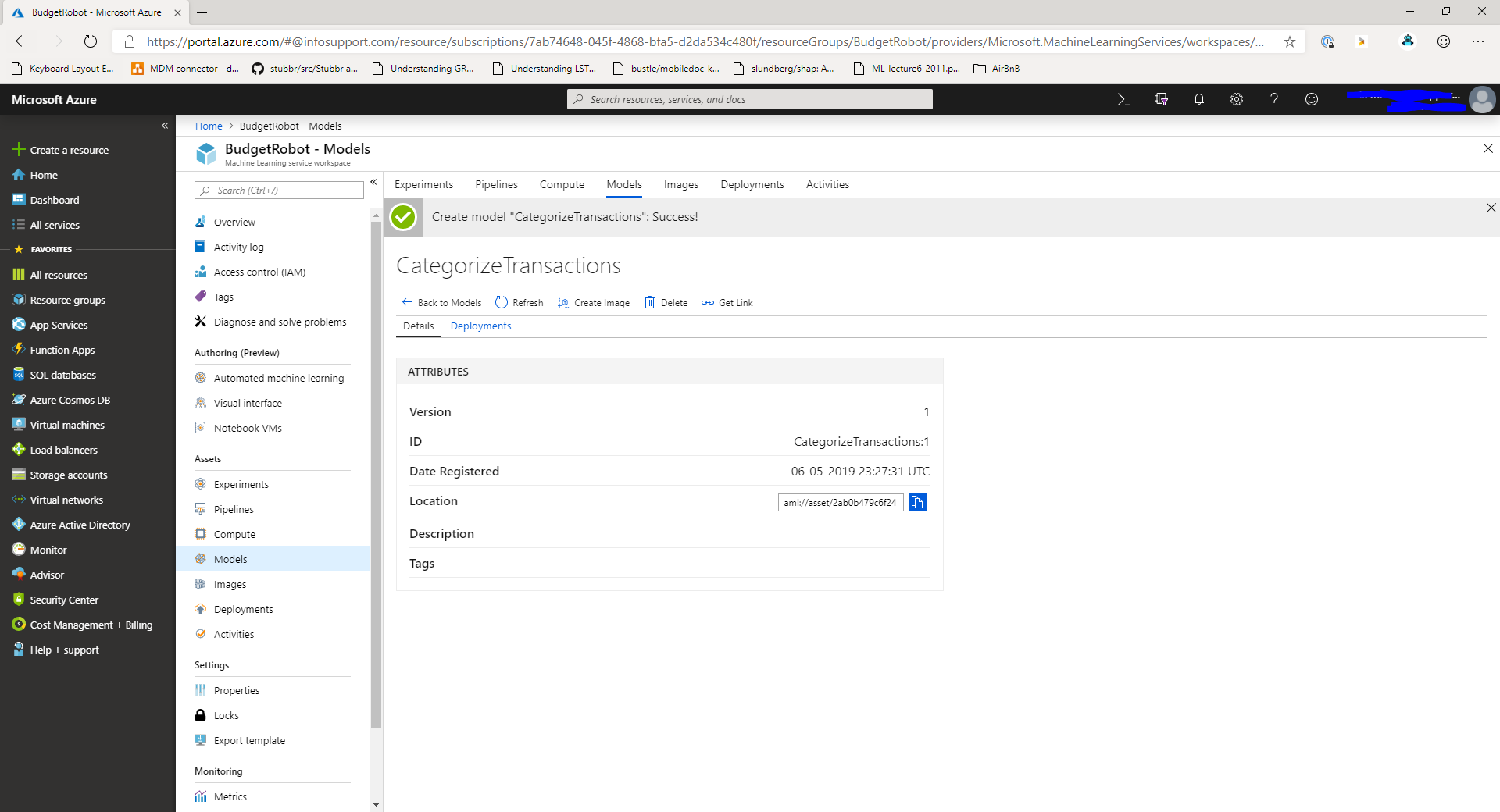
When you click the Create image button you'll get presented with a new screen that allows you to upload the scoring script and environment file.
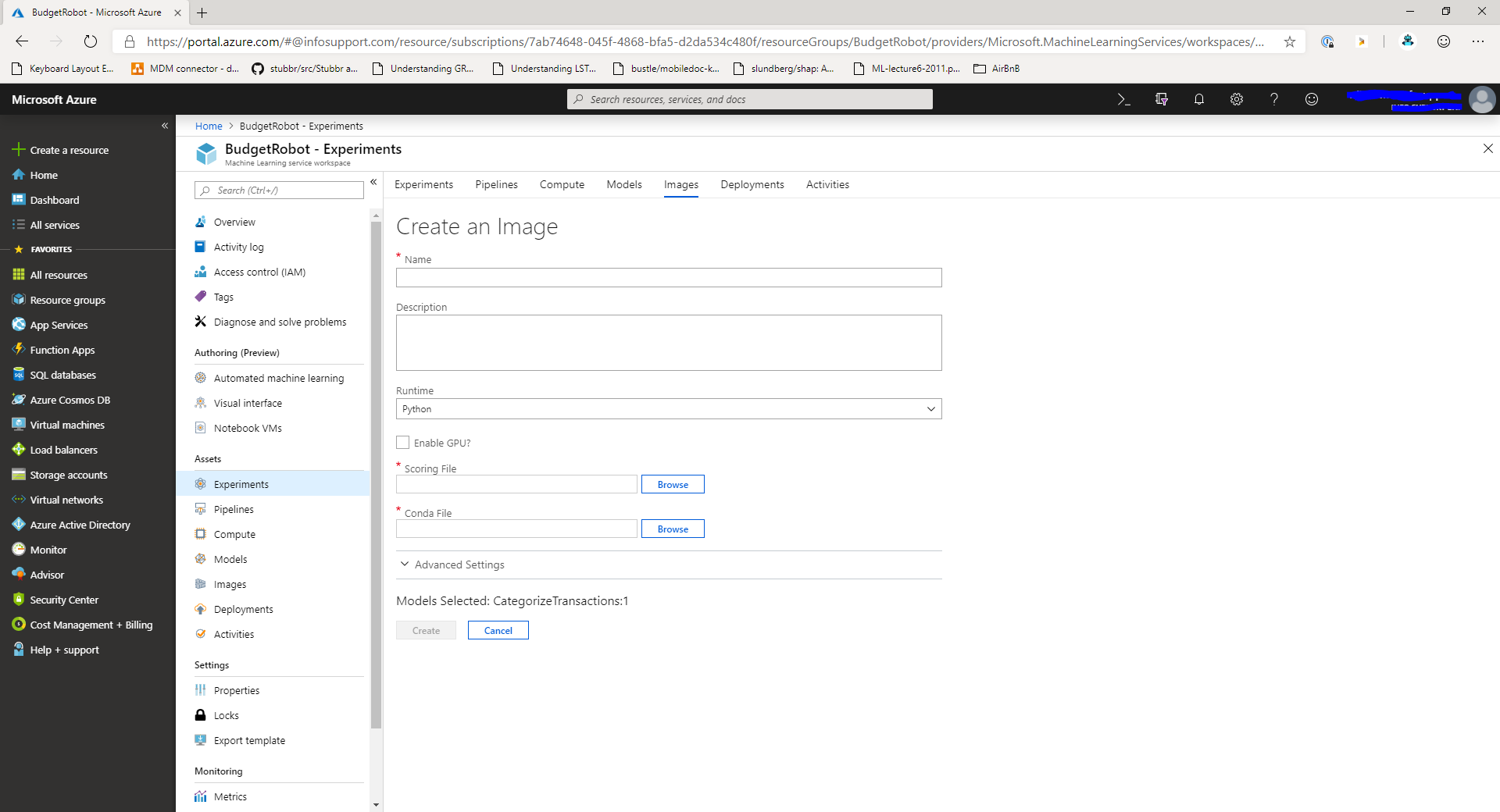
In this screen, provide a name for the image and select the scoring script and environment file for the image. Finally, click the Create button to create the new image.
It will take a while for the image to be created. This is a great opportunity to grab a drink.
The next step is to deploy the image as a docker container into production.
Deploying the image
Once the image is created, you can deploy it in the cloud either on Kubernetes or as an Azure Container Instance. To do this, you'll need to create the Create deployment button from the image details screen.
When you click the Create deployment button you'll be presented with the deployment screen.
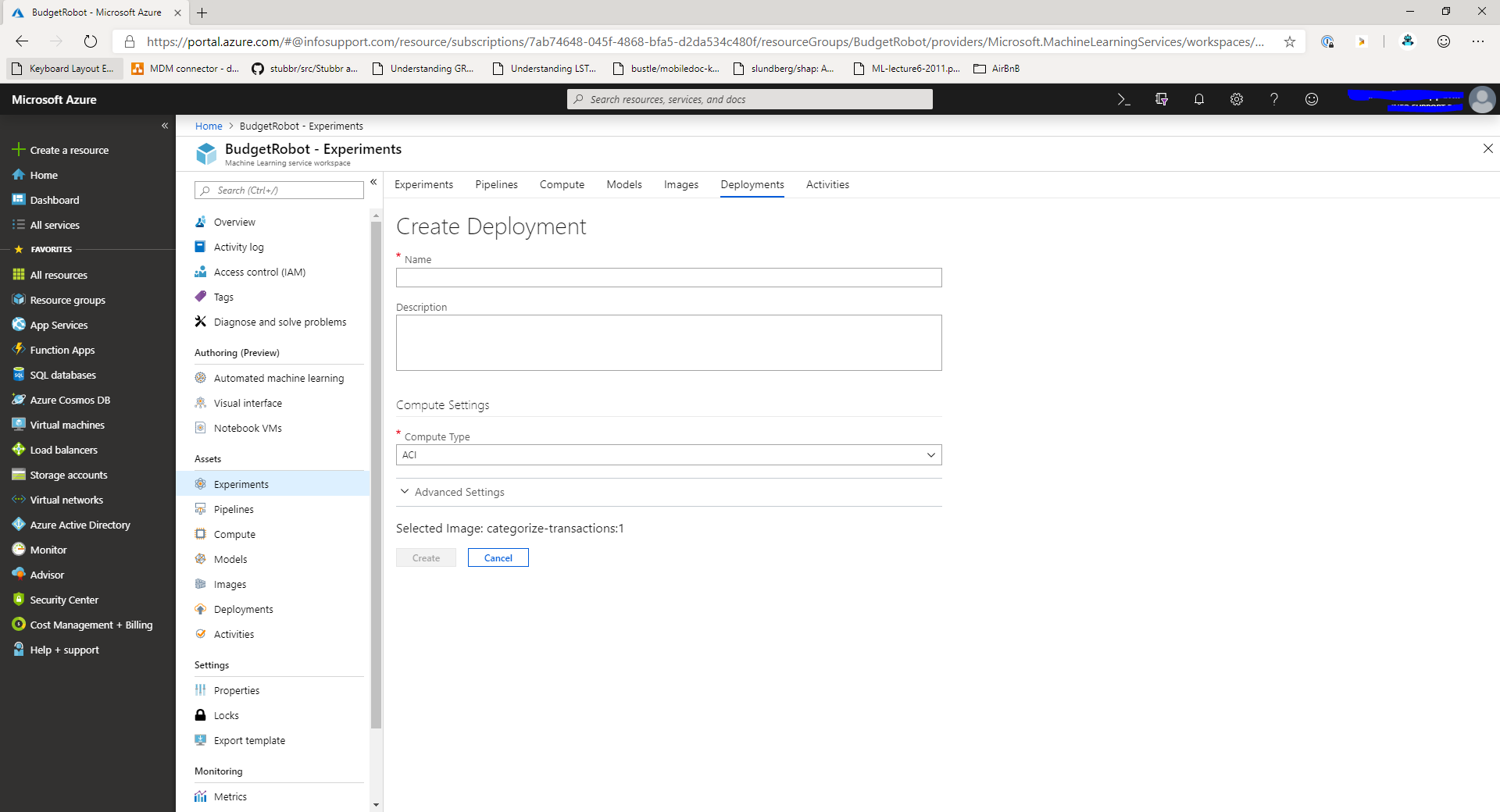
Give the deployment a name and select the type of deployment you want. The cheapest option is to use ACI (Azure Container Instance). Click the Create button to start deploying the model.
The process will take a few minutes to complete. After this you can use the model by making a HTTP request to the deployed container instance with the data you want to make a prediction for.
Summary
In this post you learned how to use Automated ML with Azure Machine Learning service to train and deploy a model trained on your data.
The Automated ML features in the portal are in public preview and will change a few times before everything is final. But it sure is a great start and I'm looking forward to what the future holds!