While chat applications have received much attention, there is so much more you can achieve by integrating language models into your projects. Imagine automating budgeting, generating engaging tweets, transforming documents, or creating compelling conference abstracts. Semantic Kernel offers a lightweight SDK that simplifies the process, allowing you to build language applications effortlessly. In this post, we'll explore how you can leverage Semantic Kernel to add powerful language skills, from installation to building skills and integrating them into your C# application. Unleash the potential of large language models and take your projects to new heights.
Why use a large language model in your application
We've all seen the hype on LinkedIn, Twitter, and regular news sites. It sometimes looks like ChatGPT is going to be the one application that everyone will use. However, I think there's more to using large language models. The real power is not in a chat application. It is in the applications that you build for other purposes!
Let me give a few examples of useful applications for large language models:
- Classifying items on your bank statement so you can budgetize your expenses without training a custom model.
- Generating tweets for your blogposts without having to write marketing texts yourself.
- Transforming your boring CV into one that clearly states what impact you made.
- Transforming your factual conference talk abstract into a compelling text that looks inviting to the audience attending the conference.
These examples are all downstream tasks that use a language model, but add to it with code that pre-processes and post-processes requests and responses. Mixing human creativity, hard rules in C#, and the probability based methods provided by AI is the ultimate combination of man and machine if you ask me.
Using a large language model can be a daunting task, because you're not going get away with just entering pieces of text. You'll need a tool like langchain or Semantic Kernel to make it easier to integrate large language models into your application.
In this post we'll discuss how you can use Semantic Kernel in your C# application to add powerful language skills.
What is Semantic Kernel?
Let's first discuss what Semantic Kernel is. The easiest way to explain this library is to show it in a picture.
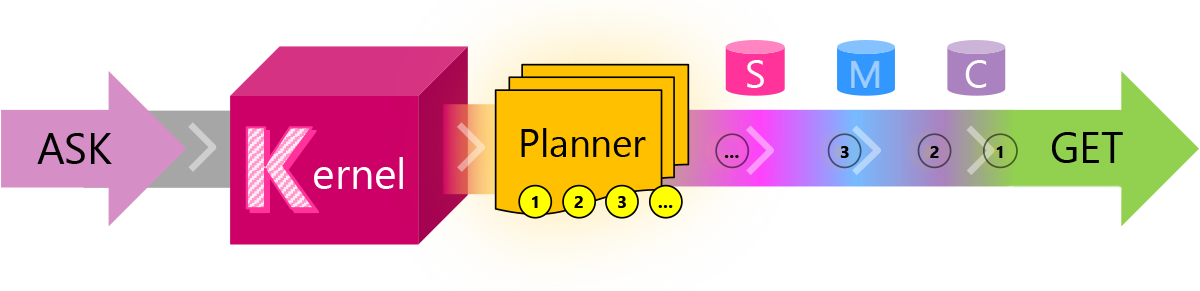
Semantic Kernel is a lightweight SDK that you can use to build language applications. There are 5 core components in the SDK:
- The kernel - This controls everything in the SDK. It connects the other components together into a cohesive language application.
- The planner - This component can combine skills and connectors. It can decide which skills to combine to build an application like a copilot.
- Skills - Skills use prompts and configuration to talk to language models to generate useful responses that you can use in your application.
- Memory - Stores documents that can provide context needed by skills. Basically, it allows you to combine a search engine with a large language model.
- Connectors - Allows your language application to use external APIs like github to extend the behavior of the language application.
There's a lot of stuff available, and I know this description doesn't do it justice at all. There's a pattern here that you should keep in mind when building applications with large language models. Start with a skill to add basic language features to your application. When you find that you need to combine skills, chain them first. If that doesn't work, at a planner to make a more informed decision of what skills to combine. Then, if you need more context, you can consider providing external content stored as vectors or in search to improve the responses that the language model gives you. Finally, use connectors if you want to build an AI agent that is more autonomous.
There are a wide range of possible applications of this library. For example:
- You can build a copilot of your own by combining the kernel with a planner and a set of skills and connectors.
- You can use the kernel with a set of skills to build a basic language feature to enhance the application with automatic summaries.
- You can build a chat experience with your own enterprise content stored in a search engine to allow the language model to give more reasonable responses to domain specific questions.
For the purpose of this post, I'm going to stick to building skills with Semantic Kernel. Let's take a look at installing Semantic Kernel.
Installing Semantic Kernel
The Semantic kernel package is available on Nuget. You can add it to your project using the following command in your terminal:
dotnet add package Microsoft.SemanticKernel
This gives you access to all the components you need to interface your application with OpenAI, Microsoft Azure OpenAI service, and DALL-E 2. Optionally, you can add a reference to the package Microsoft.SemanticKernel.Connectors.AI.HuggingFace to get access to language models stored on Hugging Face.
Setting up the kernel in your application
To use a large language model, you'll need to set up the Kernel in your application. The following code demonstrates how to do this:
var kernel = Kernel.Builder.Build();
This one line of code asks the kernel builder to create a basic kernel in which we can run commands against a language model. This by itself doesn't configure anything too fancy. You'll need to integrate the kernel with an actual language model. For example, we can integrate it with the OpenAI API using the following code.
var modelName = "text-davinci-003";
var apiKey = "<your-api-key>";
kernel.Config.AddOpenAITextCompletionService(modelName, apiKey);
The method AddOpenAITextCompletionService configure the kernel to use the completion API provided by OpenAI with the text-davinci-003 model. This is the GPT-3 model. You'll also need to configure an API key to communicate with the API.
What models can I use?
There are several models to choose from, you can find a full listing on the OpenAI website. What model you need depends on your use-case. The general rule of thumb is that you should aim for the model with the least amount of parameters for two reasons:
- Price - It costs a lot more to use the
text-davinci-003model thantext-curie-001because the former is much larger. - Speed - A smaller model is faster. Think milliseconds versus almost a minute when you have a larger model with larger input.
- Performance - If you're running a simpler task, you're more likely to get a fitting answer when you're using a smaller model.
Now that we've configured a model, let's look at building language skills for our application.
Building skills
In the introduction of this post we talked about the components in Semantic Kernel. Many of the applications will not use all of them. I think that most people will get the most value from the skills. A skill takes your input, sends it to the language model and returns the generated text. To build a skill you'll need two things:
- A configuration file to set the hyper parameters for the model
- A prompt template that's used to process the content you're sending to the model.
The models we're using support various settings called hyper parameters to control the variation in output and the length of the text generated. Let's take a look at the configuration file:
{
"schema": 1,
"type": "completion",
"description": "Generate a useful name for the project.",
"completion": {
"max_tokens": 150,
"temperature": 1.0,
"top_p": 0.0,
"presence_penalty": 0.6,
"frequency_penalty": 0.0
}
}
First, we give the Semantic Kernel library a few basic pieces of information. The type of skill we're building is a completion skill. We also provided a description for human consumption. After the basic identification information, we provide completion settings.
- The length of the response is set with
max_tokens. - The variation in response is controlled with
temperature. The higher the temperature, the more likely it is you get a different response the second time you send the same text to the model. In essence, it makes the model more human-like. - You can reduce likelyhood of repetitive responses by changing the
frequency_penaltysetting and thepresence_penaltysetting. Please note, that it's not a linear knob. It only decreases the likelyhood that you get a repetitive response. The model still can generate repeating sequences despite setting these values to a high number. There's an excellent Reddit post that explains it in more detail. - You can reduce the likely hood of strange word choice by setting the
top_pparameter. Thetop_pparameter controls what percentage of the most-likely output words are considered for generation. In short, setting this setting to0.5causes the model only to consider the top 50% of the most-likely predicted tokens in the output.
There's a lot you can tune here and it will require some experimentation to get the right settings for the job. I found that the max_tokens setting is the most important setting. You can use any settings to start with for the other parameters.
The most important part to a skill is the prompt template. A prompt template is a piece of text that contains placeholders for the input that you provide in your C# application. When we ask Semantic Kernel to invoke the language model, we'll first convert the prompt template to a prompt by filling in the variables in the template. Then after we've created the prompt, we'll call the language model.
Let's look at a prompt template to understand how it works.
Summarize the following piece of text in one sentence:
{{$input}}
Summary:
This is a basic prompt. We'll give the model an instruction and the input that we want to process. The final piece of the prompt tells the model to generate the summary without any additional output. We don't like a response that is full of mumbo jumbo.
To integrate the skill into our application we'll need to create the following directory structure:
- Skills
- Summarization
- Summarize
- skprompt.txt - The prompt template
- config.json - The hyper parameterse
In the C# application we can load the skill using the following code:
var skills = kernel.ImportSemanticSkillFromDirectory("Skills", "Summarization");
The kernel will load the Summarization skills from the Summarization folder. The output is a collection of skills. We can now call the skill using the following code:
public async Task<string> SummarizeAsync(string text)
{
var kernel = Kernel.Builder.Build();
kernel.Config.AddOpenAITextCompletionService(_modelName, _apiKey);
var skills = kernel.ImportSemanticSkillFromDirectory("Skills", "Summarization");
var input = new ContextVariables
{
["input"] = text
};
var output = await kernel.RunAsync(input, skills["Summary"]);
return output.Result;
}
Let's go over the code step by step:
- First, we build the kernel.
- Then, we connect the OpenAI completion service to the kernel
- Next, we load the summarization skills
- After that, we call
RunAsyncon the kernel with theinputvariable that's used in the Summary skill. We provide the function with our summary skill. - Finally, we return the output to the application.
We can chain skills when we call the RunAsync method. The output of one skill is automatically provided to the next skill as the INPUT variable. You can do some powerful stuff by chaining skills. For example, you can first summarize a document and then give it to a skill to classify the document into one of your choosen categories.
To chain skills easily I recommend putting related skills next to eachother in a folder under Skills. This makes them easier to find. It also makes it easier to tune skill chains. In my experiments I've found that if you reuse skills from unrelated chains you're going to have a hard time tuning your application. It sounds tempting to reuse a Summary skill across several chains, but it most likely ends up in frustration.
You've seen how to build a kernel and set up a skill, let's talk about integrating skills into a typical .NET Application.
Integrating Semantic Kernel with ASP.NET Core
Depending on your use case you'll need multiple skills in your application with possibly a few chains of skills. I'm building an application in ASP.NET core that uses several skill chains. To me, it looked like I could reuse the Kernel component across multiple requests. But it turns out not to be the case.
To make the discussion easier, let's call a single skill chain a language feature. When you want to integrate Semantic Kernel in ASP.NET Core you're going to have to build a new kernel for each request and language feature combination. Combining unrelated skill chains and feature configurations causes invalid behavior.
Another important thing to keep in mind here is that your application is going to be slow when you use a model like GPT-3. Response times up to a few seconds will be the new normal. Also expect to spin up a lot of instances of your microservice when you have a lot of people using your application.
Summary
Large language models can be a powerful asset to your applications. As it stands right now, they're deceptively easy to integrate as well. It will take time however to learn how to properly use them beyond the basic chat functionality. I hope this article was helpful for you to learn how to use models like GPT-3 from your C# applications. See you next time!