Building LLM applications the MLOps way

Building applications with large language models is the coolest thing around right now. At least if my LinkedIn feed is to believe. However, I keep getting a feeling of Deja Vu about this. I’ve been here before. Indeed, the models are new, but how we deploy and test them feels somewhat familiar. Someone must have changed the matrix.
In this post, we’ll look at building a generative AI application using a large language model. We’ll focus on how to approach the project from an operations and development process perspective and learn what’s new in building LLM applications and what’s not.
Let’s start by considering what components you must cover to build a successful machine-learning project.
Components in a typical machine-learning project
Gone are the days when we threw together a Python notebook with data preparation steps, visualizations, and training steps mixed into a beautiful soup. More and more people are learning that building something production-worthy takes much more effort.
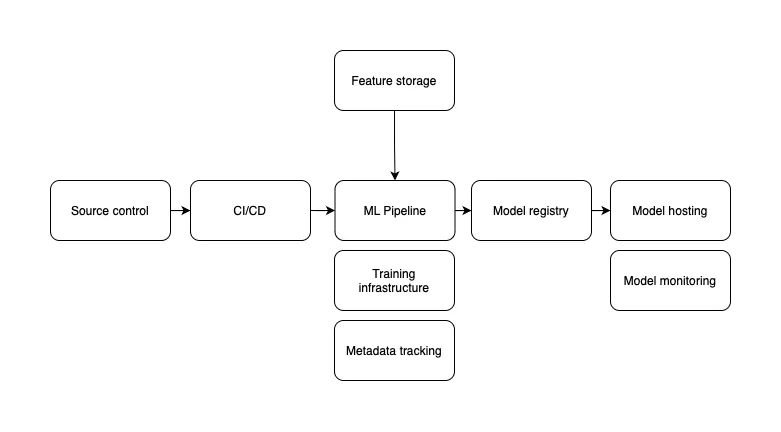
In the image, we outlined the components of a typical machine-learning project.
The core of the project is the machine-learning pipeline. The pipeline is usually implemented as a directed acyclic graph of tasks. The tasks are written in Python code that’s stored in source control.
We run machine-learning pipelines in a dedicated environment to have enough resources to train the model. Running the pipeline in a separate environment also solves the “it works on my machine” problem. Because we run in a separate environment, we need a continuous integration and deployment pipeline to update the pipeline quickly.
After a model is produced, we need to store it somewhere. This is similar to how we deploy packages and executables of applications. We have a registry for them. In the case of machine-learning projects, we have a model registry that fills in as a space where we can version models.
Finally, when we want to deploy a model to production, we must host it in a runtime environment. Typical for machine-learning models is the use of a model serving tool. Most models have a similar input and output interface, so using a model serving tool to host them makes sense.
Combining CI/CD, ML pipelines, model registries, and model serving solutions gives an average person who’s just started with ML a good headache.
But there’s one aspect that we haven’t covered yet: monitoring. Monitoring is essential to keep an eye on things while you are away. In the case of machine-learning solutions, it’s essential because machine-learning solutions fail silently. They get worse over time.
We need two forms of monitoring. We need to collect data about the machine-learning pipeline to understand how the training process progresses and what things we’ve tried. We call this experiment metadata and store it in the metadata tracking component. The other form of monitoring happens while the model is running in production. We must track errors and predictions to understand how well the machine-learning application runs.
Now that we’ve established what’s needed to run a machine-learning project, let’s talk about large language models and how they change the MLOps game.
Challenges with LLM-based applications
In the previous section, we covered the basics of MLOps. It’s an essential base for this section, where we’ll cover challenges in LLM applications and how to solve those with MLOps techniques. But before we dive into solutions, let’s look at some of the challenges we ran into at Aigency while deploying LLM applications.
Tracking which version of the LLM you use
In regular machine-learning projects, you’re building and training machine-learning models yourself, so you own the model. This gives you the advantage of knowing what data was used to train the model and what code was used to control the training process.
In the case of a large language model, you don’t typically own the model. OpenAI doesn’t tell you how they trained the model and what data they used. You can’t download the model, either. This brings along unique challenges.
As GPT-3.5, and GPT-4 receive updates, you’ll notice that your application’s behavior changes. Typically, you would store the model in your registry and track its version in the metadata store, but now you can’t.
It’s still worth tracking which version of GPT-3.5, or GPT-4 you used in your application. We recommend storing the used GPT version in your metadata store and running tests to verify that the combination of model and prompts still works.
Evaluating LLM applications is unique
Speaking of testing, evaluating how well your LLM application works is unique. You can’t look at metrics like accuracy or an error rate. There are metrics for training LLMs, but those aren’t useful when focusing on a single use case.
Typically, you want to add metrics in your ML pipeline after training a model to evaluate the model performance. In the case of LLMs, you don’t train the model yourself. But you still want to include metrics and evaluators in the pipeline. Here’s why.
A typical LLM application doesn’t just call the LLM in its purest form. Instead, you’ll have a pipeline that looks like this:
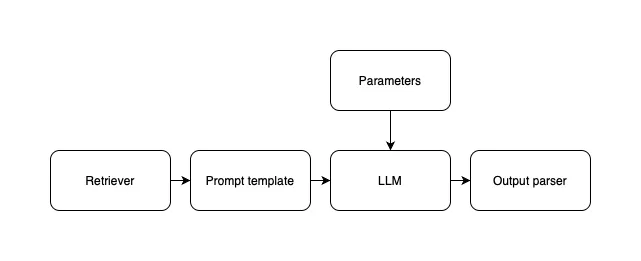
While you don’t train the LLM yourself, you do have moving parts that influence the performance of the LLM. The retrieval step, the prompt, and the parameters influence the outcome of what the LLM generates. You need to evaluate the combination.
The metrics you need to evaluate depend heavily on the use case you’re building. For example, if you build an application that answers questions based on documentation, you want to evaluate how well the response follows relevant documentation. However, if you’re building a tool that transforms text, you’ll want to ensure the response is coherent. Finally, all LLM applications suffer from malicious and harmful responses to some extent. This is another important aspect to evaluate.
You’ll need to decide which metrics to track and then store the evaluation of those metrics in your metadata tracking tool.
You may be thinking, I’m not training a model, so at least I don’t need dedicated environments for that. Well, you still need a decent amount of computing power. LLMs are slow, and evaluating several hundreds of conversations against metrics takes a long time. It’s worth investing in a good set of machines to parallelize the job if you don’t want to spend a day running evaluations.
Hosting LLM pipelines
In the previous section, we looked at evaluating and concluded that you still need considerable computing power to evaluate LLMs. Now, let’s discuss running an LLM application in production.
Many developers are hosting their LLM pipelines as part of another part of their software solution. This sounds like a good idea, but we don’t recommend it.
While you can evaluate LLMs in a lab setting, it won’t be perfect. As with all machine-learning models, statistics don’t cover what happens in production. You must run several versions of your pipelines in an A/B test to evaluate how a change will behave in production.
To make A/B testing more manageable, you need to make it easier to switch out the LLM pipeline while the application is running. We host the LLM pipeline separately from the rest of the application.
Collecting and managing features for LLM evaluation
We covered evaluating LLM applications in previous sections, but we glossed over the dataset you need to evaluate your LLM applications.
As with any ML application, you’ll want high-quality production data to evaluate the performance of your solution. And you’ll want to keep the hard-earned evaluation dataset up to date with what users do on production.
Obtaining high-quality production data for LLM applications can be hard. For example, employees who use our internal chat assistant value their privacy. We can’t just grab conversations from production. We don’t even store that data right now.
To make things easier, we recommend adding feedback options in the user interface so the user can share a conversation for analysis. Our internal solution uses a feedback queue to perform a few extra checks before we include the new data in our evaluation set. We filter out conversations with PII (Personal Identifiable Information) and ensure that the sample isn’t a prank or something unwanted.
Monitoring interactions
As a final challenge, we need to look at monitoring. Any application you run in production needs a good monitoring solution. Of course, this should include metrics like latency and alerting in case the software fails. But we also shouldn’t forget about tracing.
LLM applications are very complicated pieces of software with a lot of moving parts. This calls for a good solution to collect trace information. The trace information should include which endpoints were invoked, which functions were called, and information about errors.
In LLM applications, we need to take extra care around the LLM pipeline. Since the LLM pipeline comprises several steps, it’s a good idea to collect detailed trace information for each step in the pipeline.
As we explained at the end of our explanation of MLOps, it takes quite a lot of work to get a machine-learning model in production. A LLM solution is no different. And what’s more, not all MLOps tooling supports working with LLMs. There are a few good options though, let’s look.
MLOps tools for working with LLMs
We’ve covered several challenges around LLMs; now, let’s look at some tools that help you solve various problems. We need to be clear here most tools are still under development. But that’s to be expected.
Langchain
The first tool we must talk about is langchain. This Python package is essential when you want to build an LLM pipeline. It contains one essential concept, the runnable, that allows you to combine LLMs with tools like vector stores and even external API endpoints to build complex LLM solutions.
The ecosystem around langchain is growing very fast and contains not only the LLM pipeline building blocks but also tracing, and evaluation tools. Although we must mention that these tools are far from production ready.
Phoenix
In the previous section, we mentioned that langchain has tracing and evaluation capabilities. During testing, we found that the langchain tools for evaluation and tracing aren’t ready yet. Also, some of these tools are offered as a cloud solution. Which may or may not be suitable for your environment.
As an alternative, we can recommend using Phoenix. Phoenix focuses on providing an interface for tracing LLM pipeline calls and includes evaluation tools. The main difference with langchain is that Phoenix can be run locally without an active cloud connection.
LinguaMetrica
Regarding evaluation, it would be nice to have our tool for evaluation as well. That’s why we started building LinguaMetrica.
We mainly rolled out our own LLM evaluation tool because the current tools aren’t mature, and there is a daily stream of papers with new and better methods. We want in on the new stuff without waiting for others to add it to their tools. Also, we don’t want to write a ton of code to evaluate an LLM, which you must do when using one of the other evaluation tools.
BentoML
At Aigency, we work with bright data scientists who can code. This allows us to write our API endpoints for LLM pipelines using tools like FastAPI. However, this is wasted time when you can use a standard tool to wrap around your LLM pipeline.
We went with BentoML to package our LLM pipelines because it includes OpenAPI specifications and health endpoints out of the box. It makes getting something deployed in Kubernetes or another production environment much faster. We can choose to expose the LLM pipeline via HTTP or gRPC where we can stream responses if we have to.
For A/B testing we use Kubernetes and preferably a service mesh like Istio, but you can undoubtedly run A/B tests with a basic API gateway.
LLMOps is the next generation of MLOps
We covered quite a few MLOps-related aspects for building successful LLM applications. If you already have an existing MLOps environment, it’s good to know that you can extend the environment for LLM applications with some changes.
The new set of MLOps capabilities for LLM applications are often called LLMOps. It’s worth noting that it’s a new term that hasn’t yet settled in. But we know that things are moving quite fast.
Hope you enjoyed this post. Leave a comment or an emoji to let me know what you think!